idea 如何配置 java 的面包屑导航
本文共 138 字,大约阅读时间需要 1 分钟。
面包屑导航: 可以展示当前光标所在的方法, 用于快速确认当前所在方法和定位当前所在方法的开头
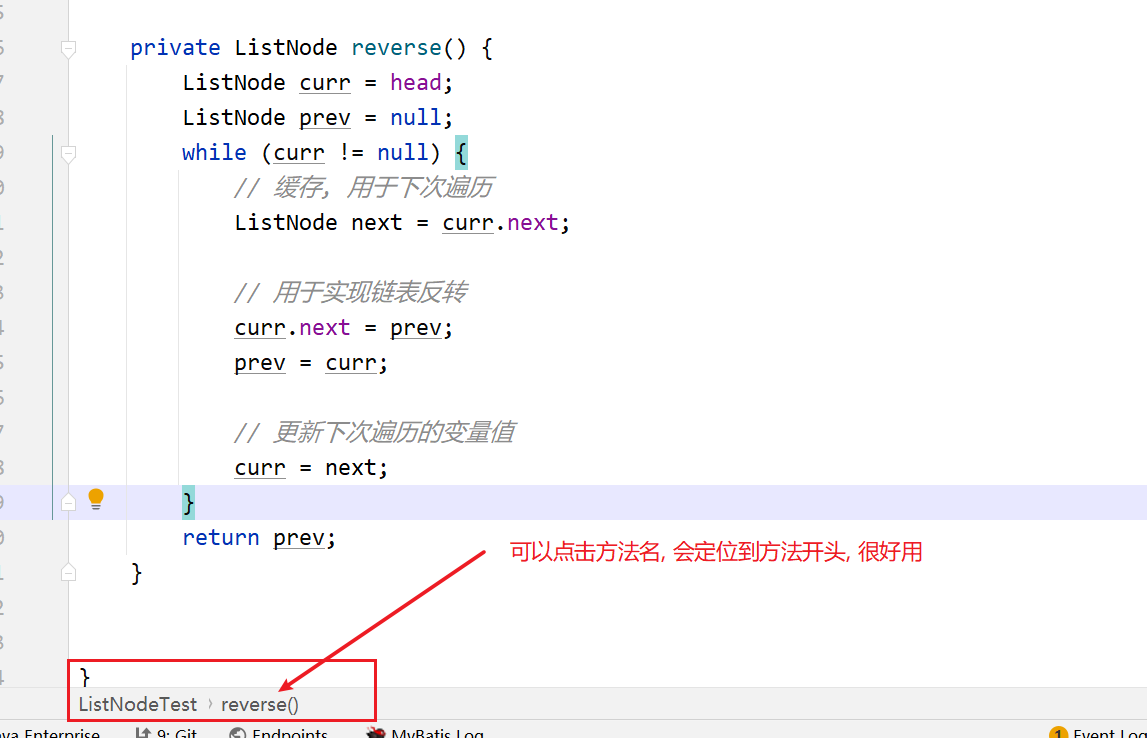
在之前的版本中, idea 该面包屑导航是开启的, 在 2020 版本后, 默认是关闭状态
editor > general > breadcrumbs > 勾选 java > ok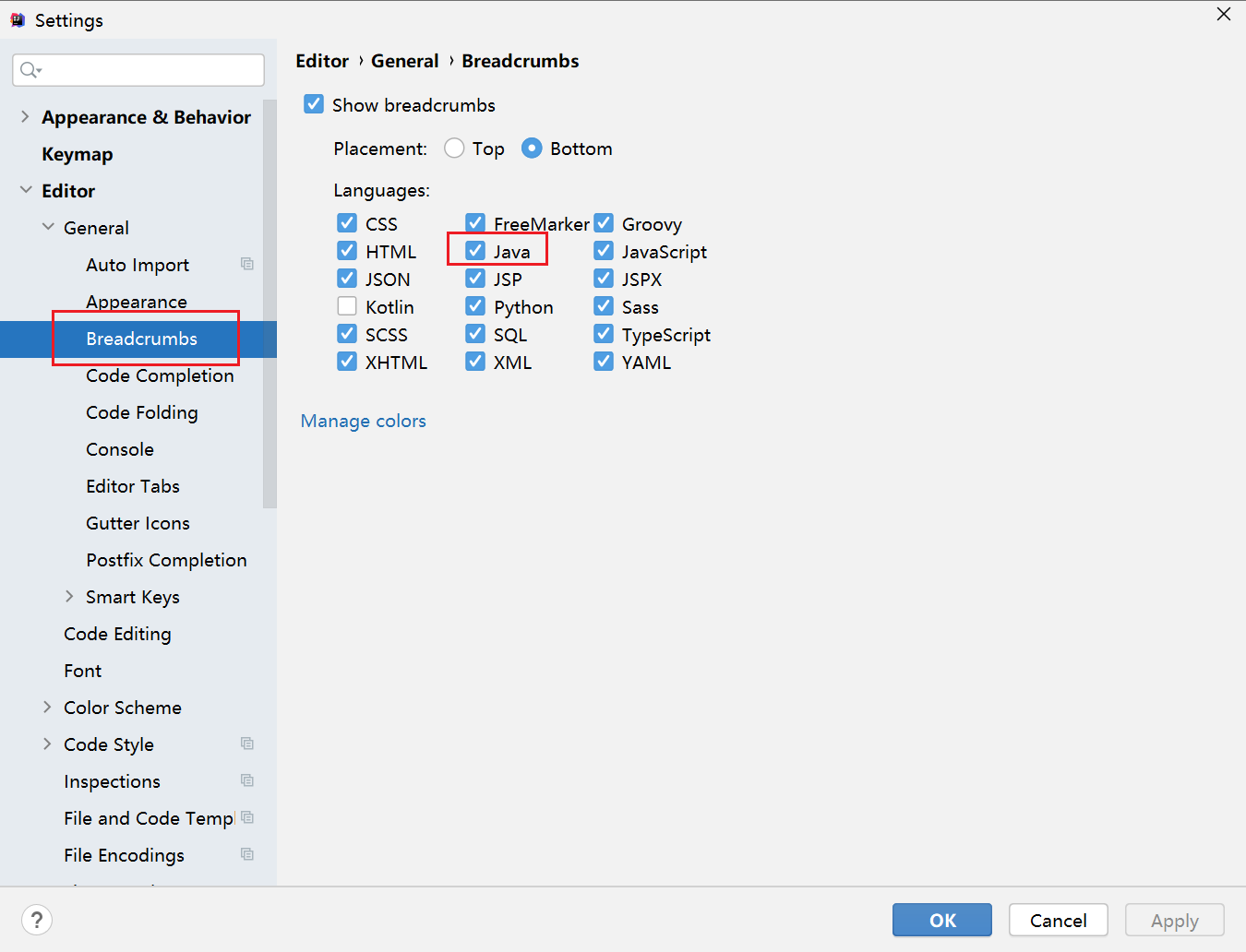
转载地址:http://gpcg.baihongyu.com/
你可能感兴趣的文章
Mysql:连接报错“closing inbound before receiving peer‘s close_notify”
查看>>
mysqlbinlog报错unknown variable ‘default-character-set=utf8mb4‘
查看>>
mysqldump 参数--lock-tables浅析
查看>>
mysqldump 导出中文乱码
查看>>
mysqldump 导出数据库中每张表的前n条
查看>>
mysqldump: Got error: 1044: Access denied for user ‘xx’@’xx’ to database ‘xx’ when using LOCK TABLES
查看>>
Mysqldump参数大全(参数来源于mysql5.5.19源码)
查看>>
mysqldump备份时忽略某些表
查看>>
mysqldump实现数据备份及灾难恢复
查看>>
mysqldump数据库备份无法进行操作只能查询 --single-transaction
查看>>
mysqldump的一些用法
查看>>
mysqli
查看>>
MySQLIntegrityConstraintViolationException异常处理
查看>>
mysqlreport分析工具详解
查看>>
MySQLSyntaxErrorException: Unknown error 1146和SQLSyntaxErrorException: Unknown error 1146
查看>>
Mysql_Postgresql中_geometry数据操作_st_astext_GeomFromEWKT函数_在java中转换geometry的16进制数据---PostgreSQL工作笔记007
查看>>
mysql_real_connect 参数注意
查看>>
mysql_secure_installation初始化数据库报Access denied
查看>>
MySQL_西安11月销售昨日未上架的产品_20161212
查看>>
Mysql——深入浅出InnoDB底层原理
查看>>